There is no better way of explaining complex ideas than with legos.
Watch the video below.
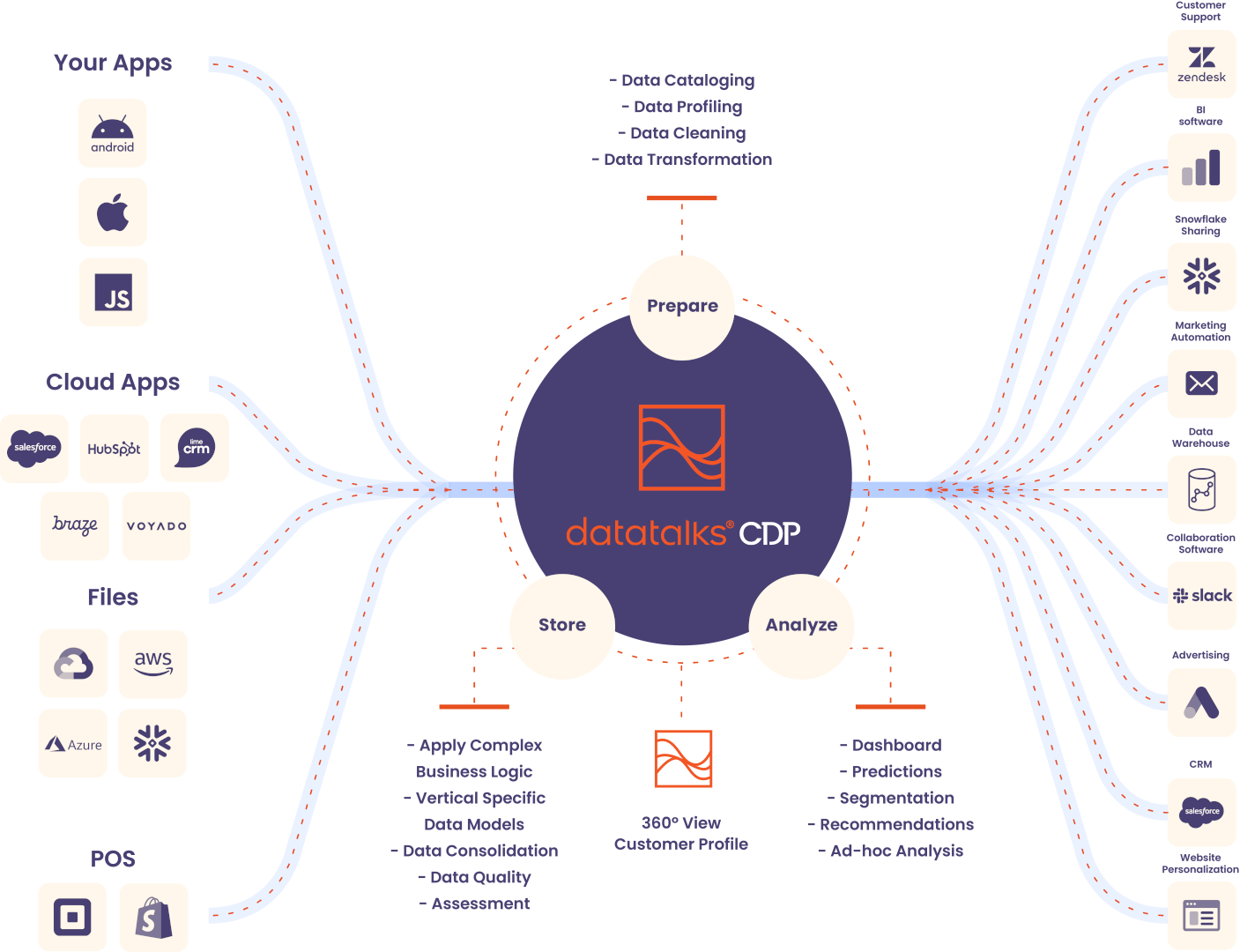
Once we gather all the relevant data, we should consolidate it into one place. The first place where all this data lands is the Data Lake. The data lake can contain structured, semi-structured and unstructured data. Data that arrives in the Data Lake, as well as, data at rest (that already exists) is being cataloged.
As soon as the data arrives in the Data Lake, the orchestrator is triggered and a set of different functions are taking place. Main purpose of the functions described below is to bring business value to the raw data stored in the Data Lake and prepare the data to be visualized or exported to external systems.




















We expose a public RESTful API to which you can send your requests without changing the schema of your data. This is the most suitable and solution when real time actions are necessary.
Data can be fetched from any third-party public API that you will point to. This allows the data collector to fetch data from third-party systems that you are using in your daily operations.
An example could be a CRM tool like Salesforce.
Receive files from the data owner. That is a good solution when real-time integration is not necessary and there is batch processing of data. The data owner can send files in the our SFTP server (csv, json). We can also fetch files from an SFTP server that you will point to.
Example of files: aggregated transactions, behavioral data, demographics etc.
Once we gather all the relevant data, we consolidate it into one place. The first place where all this data lands is the Data Lake. The data lake can contain structured, semi-structured and unstructured data. Data that arrives in the Data Lake, as well as, data at rest (that already exists) is being cataloged.
Data Cataloging is a collection of metadata(a set of data that describes and gives information about other data) that allows the data to be indexed and, thus, delivers a better data management framework. In simple words, by using Data Cataloging the data collector knows what data exists in the Data Lake and where exactly that data is.
Data Cataloging is a really crucial process when it comes to GDPR and similar compliance regulations.
The Data Cataloging process is taking place in parallel with the main process of ingesting the data in the Data Warehouse. The first step before starting processing any data is to profile it.
Data Profiling is about using statistical methods to examine the data and identify any possible outliers. By making use of Data Profiling, a statistical view can be created that shows what the expected values of the data are. That way the data platform is prepared to act when unexpected values in data are detected.
Data cleansing is the process of detecting and correcting (or dropping) corrupt or inaccurate records from a data set, and refers to identifying incomplete, incorrect, inaccurate or irrelevant parts of the data and then replacing, modifying, or deleting the dirty data.
By performing Data Cleansing it is being made sure that the data that is further processed to the Data Warehouse is consistent with data that already exists in the Data Marts and is data that can be analyzed without issues.
Data transformation is the process of converting data from one format to another, typically from the format of a source system into the required format of a destination system. The Data Lake can contain various kinds of data in different formats (CSV, JSON etc).
Trying to analyze this data directly can be very difficult unless you have top-notch Data Science skills, so a process to relationalize the data (store it in tables) can be quite helpful in this case.
The Data Warehouse contains different data models where data is stored according to the business requirements.
Each model serves a specific purpose and all together assist to convert the data from raw to a more business oriented and ready to be analyzed format. In order to store data that comes from various sources and in different formats into the data models you need to integrate the data as if it is source and format agnostic.
Data Integration is the process of combining different data sources into a single unified view. This process includes the process of Data Cleaning and Data Transformation and it ultimately enables analytics tools to produce effective, actionable business intelligence.
As a Marketer, you want to be flexible when it comes to which external channels can consume your valuable customer data. You can integrate out-of-the-box with any software system through API connectors, allowing access to data for deeper analytics while boosting customer engagements.
Hence you can:
We host a web application where you can have access to all your Dashboards and act by segmenting customers. The results of this segmentation are forwarded to the system that is responsible for acting.
Expose the data by sending them in file format to an FTP server, where you can pick the data from.
Expose the data real-time to your existing data warehouse.
Cloud platforms, like Snowflake, give the opportunity of secure Data Sharing making it really easy and safe to publish and consume data, as long as both publisher and consumer have an active account on Snowflake.
or

| Cookie | Duration | Description |
|---|---|---|
| NID | 6 months | The NID cookie contains a unique ID Google uses to remember your preferences and other information, such as your preferred language, your most recent searches, your previous interactions with an advertiser’s ads or search results, and your visits to an advertiser’s website. This helps us show you customized ads on Google. |
| Cookie | Duration | Description |
|---|---|---|
| _hjid | a year | Hotjar cookie. This cookie is set when the customer first lands on a page with the Hotjar script. It is used to persist the random user ID, unique to that site on the browser. This ensures that behavior in subsequent visits to the same site will be attributed to the same user ID. |
| VISITOR_INFO1_LIVE | 6 months | This cookie allows Youtube to check for bandwidth usage. |
| YSC | Session | Registers a unique ID to keep statistics of what videos from YouTube the user has seen. |
| Cookie | Duration | Description |
|---|---|---|
| __cfduid | a month | Cookie is set on websites using Cloudflare to speed up their load times and for threat defense services. It is does not collect or share user identification information. |
| _calendly_session | 21 days | This cookie is associated with Calendely, a Meeting Schedulers that some websites employ. This cookie allows the meeting scheduler to function within the website. |